








")












































































Consumer Research of the Future
Imagine a world where you have access to all of your consumer reviews data in one single place. A simple logon, query, and review of what was posted in the last 24 hours across all of your e-commerce channels for all of your brands and products, review star ratings rolled up in comments, consumer challenges, and consumer wins all in a matter of 10 minutes. This is the future.
Brands operating in retail are highly consumer-focused as they operate in a hyper-competitive environment. In such an environment it is critical to understand the voice of customer analytics for consumer brands. To enhance their understanding of consumer behavior, they constantly need consumer-generated data about their products. The traditional approach to getting such data has been to use surveys or research reports from companies such as Nielson, Kantar, and other market research firms. However, the emergence of e-commerce websites, social media platforms, and other online sales channels has significantly increased avenues to understand the consumers. To ensure more seamless access to such large amounts of data, brands can harvest data from these websites and store it in data lakes for future use.
Benefits of Data Harvesting and Data Lake Storage
With consumer data scattered across various online mediums, the starting point for accessing such data begins with harvesting the data across a wide variety of sources. Second, once collected, data is then housed in one central repository available for further refinement and significantly reduces the time required to source data as the need arises by various cross-functional teams. Finally, these established data pipelines provide access points for continuous data flow from source to data lake storage destination.
The diversity of such data is high yet relevant for various internal teams. For example, likes on social media validate the marketing message, dislikes and negative reviews act as a metric to improve customer experience & product quality.
Challenges in Building a Data Lake
While data lakes provide instant access to relevant data, data harvesting for data lakes that hold consumer-generated data is not without their challenges. Three key things to note when planning for a consumer reviews data lake include:
A Consumer Reviews Data Lake in Play
A large CPG company that has leaped the future of consumer reviews market research is the world’s leading consumer health and hygiene company with over 100+ brands and operations in 60+ countries. The key motivation for the company was to improve consumer satisfaction and engage directly with dissatisfied consumers to address critical concerns.
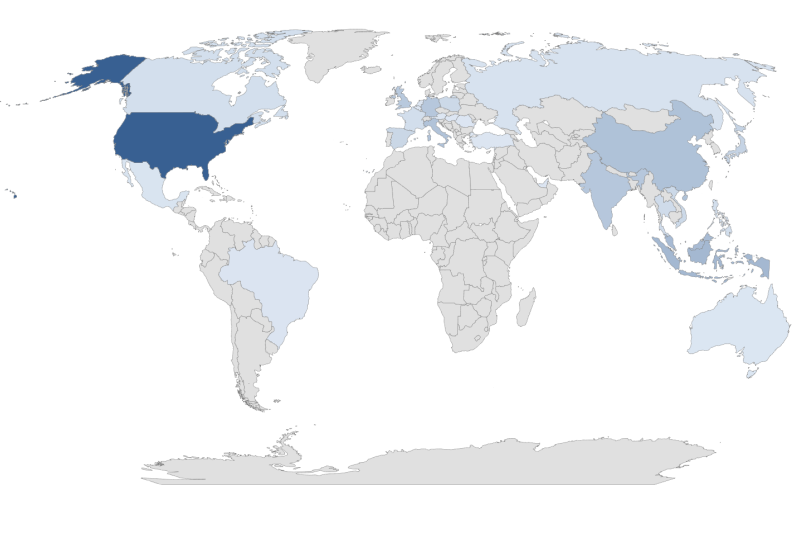
The team at SetuServ harvested consumer reviews data at the product level from 80+ sources across 29+ countries. The extracted data was then cleansed and aggregated into MongoDB and Postgres SQL databases. In addition, the Non-English reviews were translated into English. The collected information was then disseminated through APIs and PowerBI dashboards with access across the global organization.
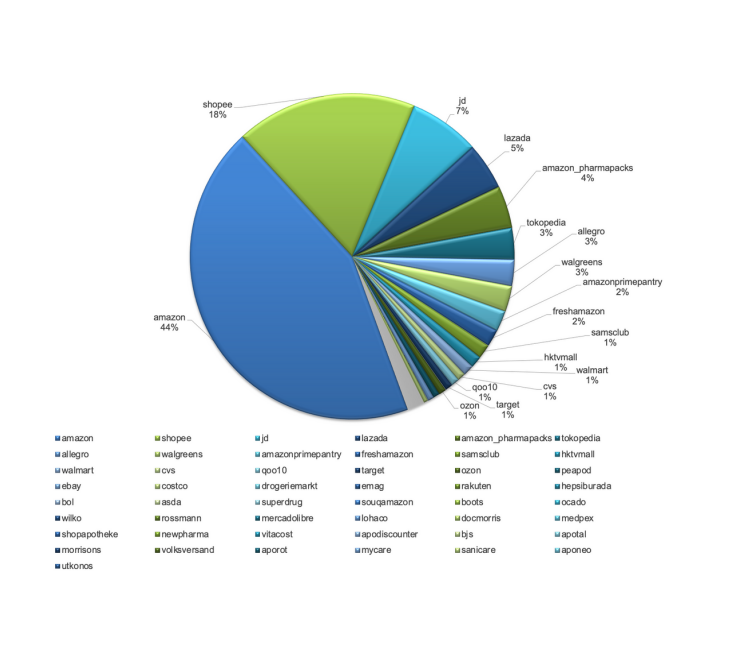
Various country managers used the extracted data in the organization to:
Because collecting data is an ongoing process, the company is able to mitigate negative sentiment faster and stay updated with market issues in real-time. The above project gives a sneak peek into how powerful data harvesting and data lakes can benefit consumer brands. To know more about data harvesting and building data lakes reach out to us at [email protected] or visit https://www.setuserv.com/ for more information.

‘Market Share’ is one of the key performance indicators for brands as it helps them understand where they rank vis-a-vis competitors and what they can learn from competitors. In addition, market share data allows brands to decide how they want to position themselves and develop their business plan. Market share is such an important metric that it is specified explicitly in their annual reports, exchange filings, and investor presentations for listed companies. Now that we have established the importance of market share data, let us understand how brands acquire this data.
The traditional approach of accessing market share data involves getting data from market research companies like Neilson and IRI. However, the information is restricted to offline sales of brands and their competitors. The last decade has seen the advent of many digital-only brands, and the covid-19 pandemic has led to accelerated online adoption as an important sales channel. Like Neilson and IRI, no equivalent data sources are available that provide market share data for brands sold online. Therefore, brands need to combine offline and online market share data to have a holistic market share picture while planning future strategies.
Challenges in computing online market share data
Almost all brands have their products listed on major e-commerce marketplaces and aggregators. Besides being listed on such marketplaces, brands are setting up their websites to establish direct relationships with consumers and to garner higher profit margins. While the presence of multiple sales avenues aides in brand visibility and increased sales, they inherently complicate the process of market share computation as,
Some e-commerce platforms like Shopee, which has operations in Southeast Asia, and HKTV Mall in Hong Kong provide data about ‘units sold’ at the SKU level. However, these platforms makeup only a fraction of the entire market, thus not fulfilling market share data computation.
A data-driven approach for getting online market share data
While most e-commerce platforms do not explicitly share the units sold for each SKU, they provide ratings and reviews for each SKU as they add credibility to the platform apart from influencing purchase decisions.
With the hypothesis that customer ratings and reviews can be used as a proxy to units sold, we started analyzing data in the geography of Indonesia. The logic behind the usage of customer reviews was that more sales trigger more reviews and more reviews convince more users to buy products.
During our analysis of e-commerce products in Indonesia, we saw a strong correlation between monthly new units and monthly new reviews. As illustrated in the following graph, the correlation between new units sold and new reviews is very strong (as indicated by an R-square of 75%).
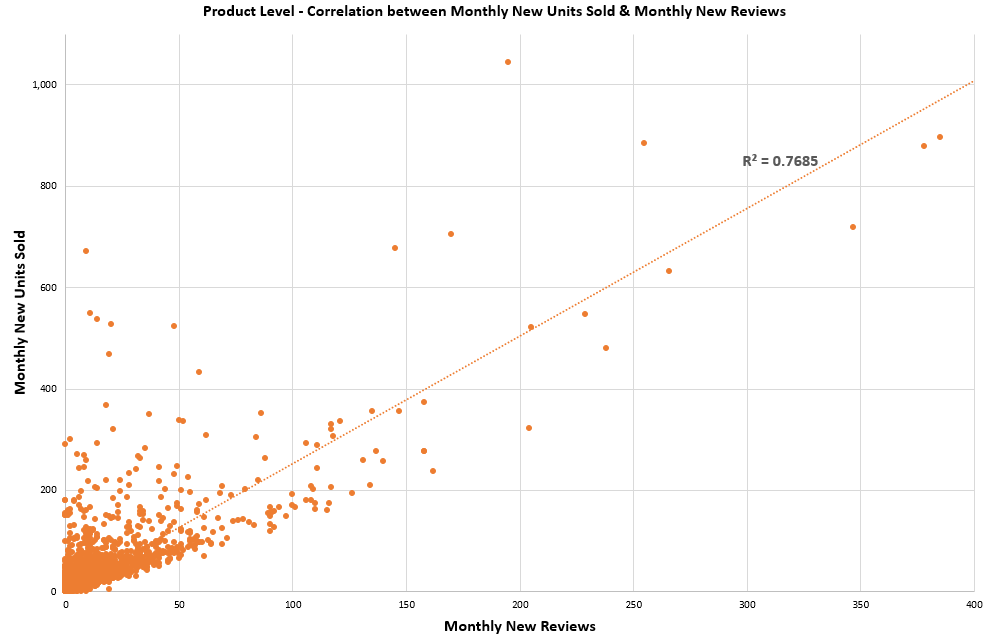
As we roll up to brand level, correlation strengthens further, as indicated by a higher R-square of 95%, due to reduced fluctuations in new units sold and new reviews.
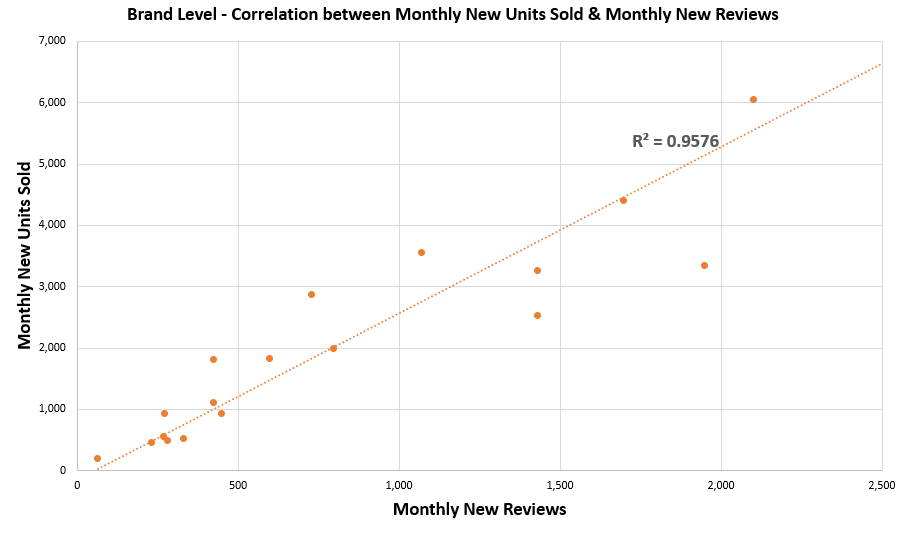
Conclusions
Such strong correlations between reviews and units sold to justify the hypothesis that ratings and reviews help quantify market share in a given category. Additionally, reviews explain why a brand is leading or trailing competitors. Finding such root causes helps brands decide the actions they need to take to improve their market share.
At SetuServ we use our proprietary machine-learning algorithm to find such root causes from large amounts of e-commerce data across multiple geographies.