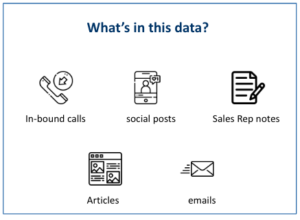
- Platform
- Solutions
Industry-specific AI solutions, while targeted, are typically modeled on generic data
- Products
- Company
About us
We are a team of data scientists, engineers and consultants committed to harnessing the vast powers of machine learning to solve distinct problems. Founded in 2012 and backed by leading investors and industry practitioners, we are experts at combining human intelligence with artificial intelligence to build custom solutions for each of our clients.
- Blog
Product development/ Innovation
Consumers talk about hundreds of unmet needs in millions of feedback comments. It’s hard to know what to act on to drive a material increase in rating or sales. Our solution mines the feedback text to both prioritize the topics to act on and quantify the respective potential increase in rating or sales.

Customer Service/ Reputation Management Automation
Consumers mention critical comments in social media and call center interactions hoping that you would respond and take action. We aggregate and organize customer comments across all feedback channels and pinpoint the critical posts you need to respond to. Additionally, our text analytics produces insights you can use to improve service agent’s effectiveness.
Marketing Content Optimization
Customers write positive posts for your products/services either organically or in response to your campaigns. Each positive post is a powerful testimonial articulating the winning attributes of your product in the words of your target customers. Our structured analysis will also surface specific language for use in marketing communication strategy, advertising copy, product descriptions and SEO tags.
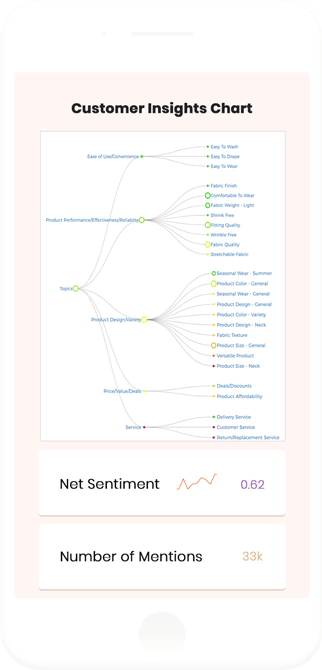
Consumer Insights
Consumers love, hate and request many characteristics for both your products and those of your competitors. We’ll benchmark you against the competitive set on each discussion topic to both pinpoint the areas where you trail and identify unmet needs you can address. We also show you which geographies, products or channels you are underperforming, and the root causes driving the under-performance.

" Setuserv’s Skierarchy approach, business knowledge and personal commitment has helped our mission greatly. They are focused, conscientious, completely reliable and all the time willing to go the extra mile to ensure effective and efficient results. "
David Vinca
(CEO)
eSparks Learning

" SetuServ's text analytics solution saves us hours of human work and money each month and is still able to preserve the quality of analyst synthesis. Their team is always pleasant and joy to work with! "
Lindsay Harden
cars.com

" SetuServ helped us derive actionable insights from thousands of reviews each day. The insights are easy to act upon by internal teams to solve customer pain points, and easy to share with a variety of stakeholders at our company. "
Saurabh Gupta
Flipkart

" The quality of the insights from SetuServ's platform is remarkable and reflects the time they spent building models specifically for us. "
Sai Koppoka
BEL USA